
지난번 포스팅에 이어, 이번에는 분류한 재무제표 데이터를 각종 지표로 만들어 보겠습니다.
이 글을 처음 보셨다면 시리즈 1, 2편을 보고 오시는게 도움이 되실 겁니다.
2021.12.02 - [프로젝트/[ing]_백테스팅_툴] - OpenDartReader 로 종목을 분류해보자 (1)
OpenDartReader 로 종목을 분류해보자 (1)
기업을 분석하는데는 기본적으로 여러 데이터가 필요합니다. 그 중에서도 기업의 기본 (펀더멘털) 이라 할 수 있는 재무데이터 분석이 필수적이라 할 수 있죠. 하지만 분석할 기업은 많습니다. 2
dragon1-honey1-wayfarer.tistory.com
2021.12.03 - [프로젝트/[ing]_백테스팅_툴] - OpenDartReader 로 종목을 분류해보자 (2)
OpenDartReader 로 종목을 분류해보자 (2)
앞선 포스팅에도 말씀 드렸듯이, 이번엔 Pykrx 를 사용해서 시가총액을 불러오고 그 데이터를 앞 포스팅의 dataframe 과 합쳐보도록 하겠습니다. 되도록 앞의 내용을 보고 오시는걸 추천드립니다 ~ 2
dragon1-honey1-wayfarer.tistory.com
1. 사용할 지표 및 계산식
사용할 지표는 6개이며 사용한 계산식은 아래와 같습니다. 영문 풀네임까지는 기재하지만 세부 설명은 여기선 다루지 않고, 기회가 된다면 따로 포스팅 해보도록 하겠습니다.
PER (Price Earning Ratio) : 시가총액 / 당기순이익
PBR (Price Book-value Ratio) : 시가총액 / 부채총계
PSR (Price Sales Ratio) : 시가총액 / 매출액
GP/A (Gross Profit / Asset) : 매출총이익 / 자산총계
POR (Price Operating earning Ratio) : 시가총액 / 영업이익
PCR (Price Cashflow Ratio) : 시가총액 / 영업활동현금흐름
PFCR (Price Free Cashflow Ratio) : 시가총액 / 잉여현금흐름
NCAV / MK : 청산가치 (유동자산 - 부채총계) / 시가총액
여기서 시가총액 , 청산가치를 제외하고 모두 최근 4분기의 합으로 계산됩니다.
2. 코드
코드로 표현하면 아래와 같습니다.
앞 포스팅의 코드와 연계되는 부분이 있기 때문에 한번 보고오시는 걸 추천드립니다.
처음에 재무데이터를 분류했으므로 코드작성엔 큰 어려움이 없을 것입니다.
import pandas as pd
file_path = ' '
df2 = pd.read_excel(file_path)
length = len(df2)
df4 = pd.DataFrame(columns=['PER','PBR','PSR','GP/A','POR','PCR','PFCR','NCAV/MK'], index=['1900-01-01'])
for i in range(3, length):
indexing = df2.iloc[i]['Unnamed: 0']
PER = df2.iloc[i]['시가총액'] / (df2.iloc[i-3]['당기순이익'] + df2.iloc[i-2]['당기순이익'] + \
df2.iloc[i-1]['당기순이익'] + df2.iloc[i]['당기순이익'])
PBR = df2.iloc[i]['시가총액'] / df2.iloc[i]['부채총계']
PSR = df2.iloc[i]['시가총액'] / (df2.iloc[i-3]['매출액'] + df2.iloc[i-2]['매출액'] + \
df2.iloc[i-1]['매출액'] + df2.iloc[i]['매출액'])
GP_A = (df2.iloc[i-3]['매출총이익'] + df2.iloc[i-2]['매출총이익'] + \
df2.iloc[i-1]['매출총이익'] + df2.iloc[i]['매출총이익']) / df2.iloc[i]['자산총계']
POR = df2.iloc[i]['시가총액'] / (df2.iloc[i-3]['영업이익'] + df2.iloc[i-2]['영업이익'] + \
df2.iloc[i-1]['영업이익'] + df2.iloc[i]['영업이익'])
PCR = df2.iloc[i]['시가총액'] / (df2.iloc[i-3]['영업활동현금흐름'] + df2.iloc[i-2]['영업활동현금흐름'] + \
df2.iloc[i-1]['영업활동현금흐름'] + df2.iloc[i]['영업활동현금흐름'])
PFCR = df2.iloc[i]['시가총액'] / (df2.iloc[i-3]['잉여현금흐름'] + df2.iloc[i-2]['잉여현금흐름'] + \
df2.iloc[i-1]['잉여현금흐름'] + df2.iloc[i]['잉여현금흐름'])
NCAV_MK = (df2.iloc[i]['유동자산'] - df2.iloc[i]['부채총계']) / df2.iloc[i]['시가총액']
df4.loc[indexing] = [PER, PBR, PSR, GP_A, POR, PCR, PFCR, NCAV_MK]
df4.drop(['1900-01-01'], inplace=True) # 첫 행 drop
이에 대한 결과값은 아래와 같습니다.
PER PBR PSR GP/A POR PCR PFCR NCAV/MK
2016-09-30 6.524478 3.486368 0.648325 0.557579 4.875545 2.960805 8.404698 0.296976
2016-12-30 11.154763 3.662757 1.255800 0.311201 8.669574 5.349809 38.305172 0.284881
2017-03-31 11.519340 3.895184 1.430176 0.320087 8.927008 5.882506 106.445252 0.189389
2017-06-30 10.229152 4.039856 1.460299 0.330867 8.091504 6.424510 187.947487 0.178008
2017-09-30 8.987831 3.873987 1.466216 0.345560 6.972636 6.466181 167.258628 0.178630
2017-12-30 7.797306 3.769659 1.373025 0.365481 6.131843 5.291701 -54.955859 0.181557
2018-03-31 6.840285 3.541618 1.265905 0.372983 5.320177 4.703094 -1808.570997 0.208029
2018-06-30 6.484588 3.499873 1.212033 0.361338 4.975160 4.391399 -87.889628 0.238472
2018-09-30 6.194251 3.135655 1.190402 0.345127 4.715535 4.497717 -41.002329 0.272285
2018-12-30 5.149282 2.492730 0.936714 0.328200 3.877689 3.406502 -27.852701 0.363895
2019-03-31 7.070332 2.901936 1.131403 0.296643 5.387283 4.704406 -16.212020 0.320899
2019-06-30 8.812992 3.293457 1.202978 0.277997 6.809228 5.632219 -19.502607 0.314493
2019-09-30 11.724902 3.255567 1.274333 0.246417 9.322785 6.088467 -24.157418 0.328185
2019-12-30 15.323425 3.714303 1.445801 0.235876 11.996102 7.340072 -65.909149 0.275285
2020-03-31 13.209193 3.130094 1.221636 0.235107 10.186952 5.485192 -162.592376 0.335617
2020-06-30 14.357032 3.575706 1.369385 0.237229 10.673394 5.238412 43.044914 0.310862
2020-09-30 13.882249 3.486527 1.477592 0.239236 10.186761 5.743823 -101.745976 0.299280
2020-12-30 18.310946 4.727376 2.041968 0.244077 13.434296 7.406564 -55.576499 0.198382
2021-03-31 16.952633 4.098767 1.968403 0.243590 12.482605 7.224781 2168.127728 0.186438
2021-06-30 14.712972 4.702249 1.870368 0.263099 11.113336 7.463556 -113.477070 0.184044
2021-09-30 12.399177 3.892151 1.671868 0.256617 9.449300 6.412368 61.175786 0.224112
3. 비교
(1). 네이버 금융
앞의 계산 데이터와 네이버 금융의 데이터를 비교 해보겠습니다. 대표적으로 PER 을 살펴보면
네이버 금융에서 나와있는 지표는
PER = 수정 주가 (보통주) / EPS
EPS = 당기순이익 / (주식수정평균발행주식수, 보통주 + 우선주)
로 계산합니다.
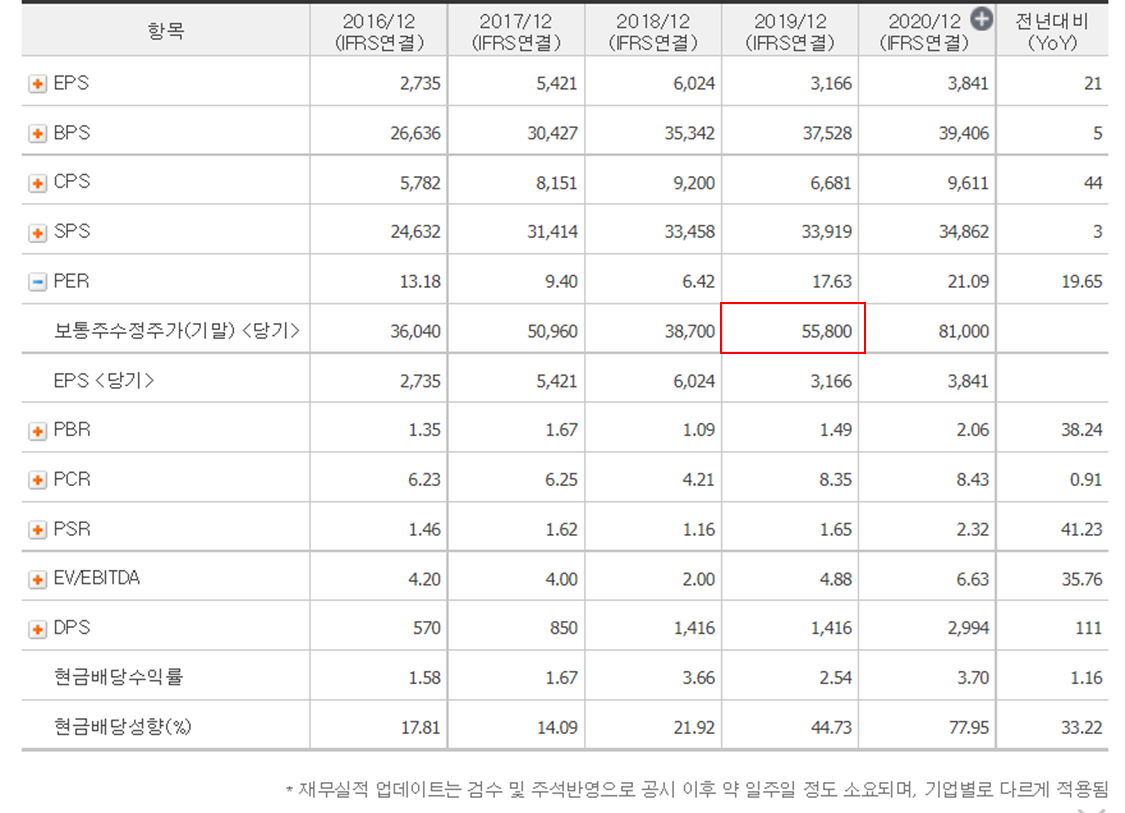

실제 보통주 수정주가를 차트에 보면 위의 값과 일치함을 확인할 수 있습니다.

'수정'주가라고 하는건 액면분할 / 합병을 거친 현재시점에서 그 이전 과거시점의 주가나 주식수를 환산할 때 스케일의 차이가 나므로 이를 현재시점에 맞게 보정해 주는걸 의미합니다.
PER 에서도 확인했듯이, 다른 지표들도 마찬가지의 방식을 사용하고 있습니다.
(2). 블로그 포스팅
반면 제 포스팅에서 계산한 값은
PER = 시가총액 (해당일 수정주가 * 보통주 발행주식수) / 당기순이익
으로 구성되어 있어 우선주가 빠져있습니다.
다른 시가총액을 활용하는 지표도 마찬가지의 이유로 차이가 남을 알 수 있습니다.
요약하자면, 우선주를 반영하냐 / 안하냐의 차이에 따른 지표값 차이라고 보시면 되겠습니다.
(3). 맞추고 싶다면...
제 블로그에선 우선주를 제외한 방법으로 계속 포스팅을 진행할 예정이지만, 만약 네이버 금융과 지표를 똑같이 맞추고 싶다고 한다면 액면분할 / 합병이 미반영된 2가지 준비물이 필요합니다.
(1). 해당 시점의 유통주식수 (보통주 + 우선주)
(2). 해당 시점의 주가
첫번째. 해당 시점의 유통주식수는 OpenDartReader 에는 따로 함수가 없지만, OpenDartReader 내부의 코드를 참고하여 코드 수정을 한다면 활용할 수 있습니다. 결과에서 distb_stock_co column 의 합계행에 있습니다.

수정된 코드는 아래와 같습니다.
import requests
import json
import OpenDartReader
try:
from pandas import json_normalize
except ImportError:
from pandas.io.json import json_normalize
# 3-1 상장기업 주식수 (다중회사 기능 불가)
def stock_amount(api_key, corp_code, bsns_year, reprt_code='11011'):
url = 'https://opendart.fss.or.kr/api/'
url += 'stockTotqySttus.json' # 원하는 페이지 추가. 개발가이드 참조
corp_code = dart.find_corp_code(corp_code)
params = {
'crtfc_key': api_key,
'corp_code': corp_code,
'bsns_year': bsns_year, # 사업년도
'reprt_code': reprt_code, # "11011": 사업보고서
}
r = requests.get(url, params=params)
jo = json.loads(r.text)
if 'list' not in jo:
return None
return json_normalize(jo, 'list')
api_key = ' '
dart = OpenDartReader(api_key)
a = stock_amount(api_key, '005930', '2016', '11011') # 데이터프레임 내 값이 , 가 붙어있는 str 타입.
total_amount = a.iloc[2]['distb_stock_co'].replace(",","") # 문자열의 , 를 제거한다.
total_amount = int(total_amount)
print(total_amount)
두번째. 해당시점의 주가는 pykrx 에서 가져올 수 있습니다.
이 또한 코드로 나타내보면 ...
from pykrx import stock
import pandas as pd
import matplotlib.pyplot as plt
df = stock.get_market_ohlcv_by_date("20180104","20181231","005930", adjusted=False)
print(df)
plt.plot(df.index, df['종가'])
plt.show()
마지막엔 알아보기 쉽게 그래프로 간단하게 나타내보았습니다.
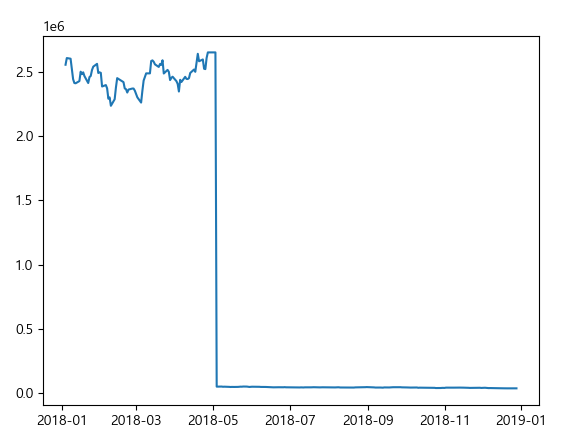
액면분할의 양이 커서 액면분할 이후엔 값이 잘 나타나질 않네요 ㅎㅎ
이 두개를 잘 활용하시면 네이버 금융에 나와있는 투자지표와 똑같이 맞출 수 있을 거라 생각합니다.
시간이 되면 한번 도전해보겠습니다.
다음 포스팅은 가져오고 가공한 데이터를 바탕으로 기업들을 비교하는 걸 해보도록 하겠습니다.
(시간이 오래 걸린다면 잠시 다른걸 했다가 하는걸로...)
'프로젝트 > [ing]_백테스팅_툴' 카테고리의 다른 글
| [Python] 백트레이더(Backtrader)에서 현금흐름지표(MFI) 를 사용하자 (0) | 2022.03.04 |
|---|---|
| OpenDartReader 로 종목을 분류해보자 (4) - 근데 pykrx를 곁들인... (2) | 2022.01.12 |
| OpenDartReader 로 종목을 분류해보자 (2) (0) | 2021.12.03 |
| OpenDartReader 로 종목을 분류해보자 (1) (2) | 2021.12.02 |
| [python] 인터넷 연결 안되있으면 컴퓨터 다시 시작하는 프로그램 (0) | 2021.10.21 |